publications
2025
-
 Improving Multi-Turn Tool Use with Reinforcement Learning (200K+ Views on X)Richard Zhuang* , Trung Vu* , Alex Dimakis , and 1 more author2025
Improving Multi-Turn Tool Use with Reinforcement Learning (200K+ Views on X)Richard Zhuang* , Trung Vu* , Alex Dimakis , and 1 more author2025Recently, OpenAI has demonstrated that RL can be used to train a research agent that uses tools to carry out complex, multi-step workflows. However, they did not disclose a lot of details about their training recipe. Meanwhile, experiments in the open-source and research community are often single-turn, lacking back-and-forth interaction with an environment. We are excited to share some recent findings which show that RL can improve multi-step tool use capabilities, a first milestone. Using GRPO, the core algorithm behind DeepSeek-R1, we improved Qwen2.5-7B-Instruct’s tool use performance by 23% on a subset of the BFCL benchmark using only 100 training samples. The tasks in this benchmark require an agent to orchestrate multiple tools to complete multi-step tasks in a simulated environment, such as booking air travel using credit cards and placing orders in a trading system.
-
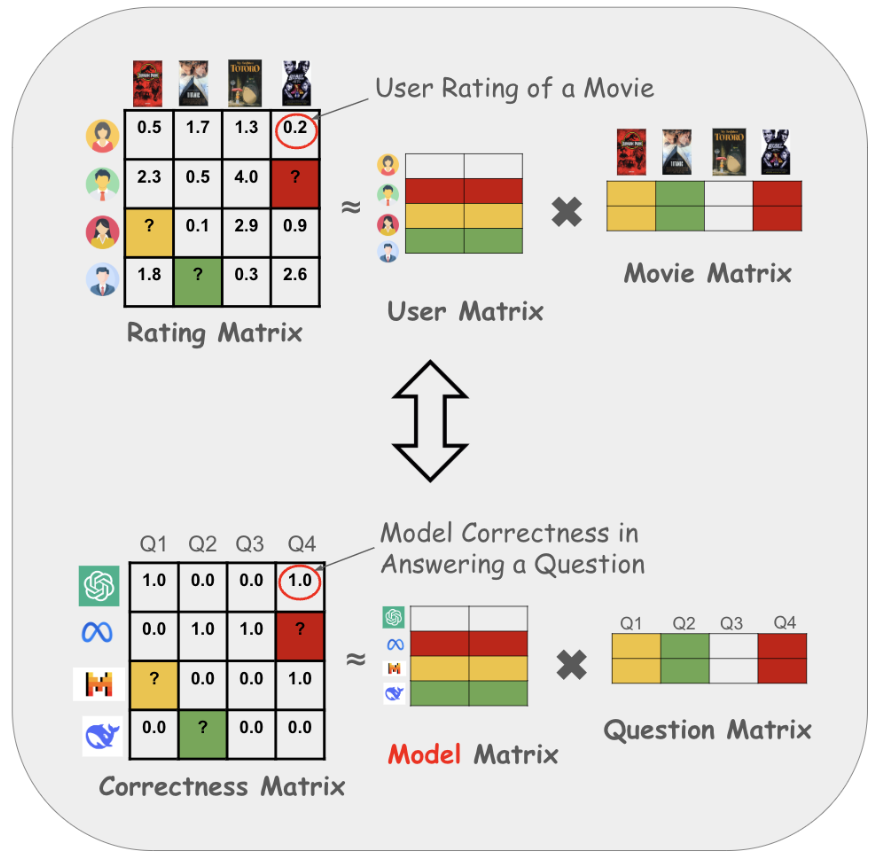 EmbedLLM: Learning Compact Representations of Large Language Models (ICLR 2025 Spotlight🌟)Richard Zhuang , Tianhao Wu , Zhaojin Wen , and 3 more authorsIn The Thirteenth International Conference on Learning Representations (ICLR) , 2025
EmbedLLM: Learning Compact Representations of Large Language Models (ICLR 2025 Spotlight🌟)Richard Zhuang , Tianhao Wu , Zhaojin Wen , and 3 more authorsIn The Thirteenth International Conference on Learning Representations (ICLR) , 2025With hundreds of thousands of language models available on Huggingface today, efficiently evaluating and utilizing these models across various downstream tasks has become increasingly critical. Many existing methods repeatedly learn task-specific representations of Large Language Models (LLMs), which leads to inefficiencies in both time and computational resources. To address this, we propose EmbedLLM, a framework designed to learn compact vector representations of LLMs that facilitate downstream applications involving many models, such as model routing. We introduce an encoder-decoder approach for learning such embedding, along with a systematic framework to evaluate their effectiveness. Empirical results show that EmbedLLM outperforms prior methods in model routing. Additionally, we demonstrate that our method can forecast a model’s performance on multiple benchmarks, without incurring additional inference cost. Extensive probing experiments validate that the learned embeddings capture key model characteristics, e.g. whether the model is specialized for coding tasks, even without being explicitly trained on them. We open source our dataset, code and embedder to facilitate further research and application.
-
 PokerBench: Training Large Language Models to become Professional Poker Players (AAAI 2025)Richard Zhuang , Akshat Gupta , Richard Yang , and 3 more authorsIn The 39th Annual AAAI Conference on Artificial Intelligence (AAAI) , 2025
PokerBench: Training Large Language Models to become Professional Poker Players (AAAI 2025)Richard Zhuang , Akshat Gupta , Richard Yang , and 3 more authorsIn The 39th Annual AAAI Conference on Artificial Intelligence (AAAI) , 2025We introduce PokerBench - a benchmark for evaluating the poker-playing abilities of large language models (LLMs). As LLMs excel in traditional NLP tasks, their application to complex, strategic games like poker poses a new challenge. Poker, an incomplete information game, demands a multitude of skills such as mathematics, reasoning, planning, strategy, and a deep understanding of game theory and human psychology. This makes Poker the ideal next frontier for large language models. PokerBench consists of a comprehensive compilation of 11,000 most important scenarios, split between pre-flop and post-flop play, developed in collaboration with trained poker players. We evaluate prominent models including GPT-4, ChatGPT 3.5, and various Llama and Gemma series models, finding that all state-of-the-art LLMs underperform in playing optimal poker. However, after fine-tuning, these models show marked improvements. We validate PokerBench by having models with different scores compete with each other, demonstrating that higher scores on PokerBench lead to higher win rates in actual poker games. Through gameplay between our fine-tuned model and GPT-4, we also identify limitations of simple supervised fine-tuning for learning optimal playing strategy, suggesting the need for more advanced methodologies for effectively training language models to excel in games. PokerBench thus presents a unique benchmark for a quick and reliable evaluation of the poker-playing ability of LLMs as well as a comprehensive benchmark to study the progress of LLMs in complex game-playing scenarios.
2024
-
 Evolving AI Collectives Enhance Human Diversity and Enable Self-Regulation (ICML 2024)Shiyang Lai , Yujin Potter , Junsol Kim , and 3 more authorsIn Forty-first International Conference on Machine Learning (ICML) , 2024
Evolving AI Collectives Enhance Human Diversity and Enable Self-Regulation (ICML 2024)Shiyang Lai , Yujin Potter , Junsol Kim , and 3 more authorsIn Forty-first International Conference on Machine Learning (ICML) , 2024Large language model behavior is shaped by the language of those with whom they interact. This capacity and their increasing prevalence online portend that they will intentionally or unintentionally “program” one another and form emergent AI subjectivities, relationships, and collectives. Here, we call upon the research community to investigate these “societies” of interacting artificial intelligences to increase their rewards and reduce their risks for human society and the health of online environments. We use a small “community” of models and their evolving outputs to illustrate how such emergent, decentralized AI collectives can spontaneously expand the bounds of human diversity and reduce the risk of toxic, anti-social behavior online. Finally, we discuss opportunities for AI cross-moderation and address ethical issues and design challenges associated with creating and maintaining free-formed AI collectives.